Usage¶
We provide here a description of the ccrawl command-line tool which defines several sub-commands. Of course, this tool can be used as well as a traditional Python package.
The first step is to build a local database from C and/or C++ (header) files. The libclang library is used to extract the following features:
- definitions of macros (#define)
- definitions of simple types (typedef)
- definitions of structured types (struct, union, enum, class & template)
- definitions of function types (prototypes)
Since files are only parsed and not compiled by libclang, the set of included files can be imcomplete and syntax errors only lead to ignored definitions. Of course, many queries do require ultimately that all subtypes of a structure have been collected but this is not enforced by ccrawl at parsing time. Note that comments associated to these features are extracted when provided by libclang.
The local database is a TinyDB JSON Storage file. For performance and scaling reasons, ccrawl supports also the use of a remote MongoDB database allowing massive indexing of the samples built locally.
Commands¶
These global options which apply to all commands are:
$ ccrawl [-v, --verbose] display more infos
[-q, --quiet] don't display anything
[-c, --config <file>] path to configuration file
[-l, --local <file>] path to local database file
[-b, --db <url>] url for the remote database
[-g, --tag <name>] filter queries with given tag
[--help] show this message
[<command> [options] [args]]
All default parameters are possibly overwritten by a configuration file (which defaults to $HOME/.ccrawlrc unless provided with the -c option.) The format of the configuration file is based on the traitlets python package. Parameters allow to set the default python interpreter, the mandatory pathname of the libclang library required by the libclang python wrapper, the default local database path or remote database url.
Documents of the local database are stored with the following json format:
{'cls': '<class>',
'id' : '<identifier>',
'src': '<path>',
'tag': '<name>',
'val': <object>}
For example, structure struct _mystruct in file “samples/header.h” is stored as:
{'cls': 'cStruct',
'id': 'struct _mystruct',
'src': 'samples/header.h',
'tag': '1654709776.1331487',
'val': [['myinteger', 'I', None],
['int [12]', 'tab', None],
['unsigned char [16]', 'p', None],
['short *', 's', None],
['struct _mystruct *', 'next', None],
['foo', 'func', None],
['struct _bar [2]', 'bar', None]
]}
(Notice that if no --tag global option is provided, the default tag name is constructed from
the current collect time.)
Collect¶
The collect command locally extracts definitions from the provided sources <src>:
$ ccrawl [global options] collect [options] <src>
options: [-a, --all] by default, only header files with '*.h' extension are
considered, this option forces extraction from all provided
files.
[-t, --types] extraction is limited to types (typedefs, struct, union, enum)
[-f, --functions] extraction is limited to function prototypes
[-m, --macros] extraction is limited to macros
[-s, --strict] collect in "strict" mode: in this mode, all errors reported by
libclang are blocking. It is thus mandatory to provide the
complete set of input files and precise clang options such that
clang is able to compile successfully the provided <src> files.
[--clang "<opts>"] pass <opts> string directly to clang as options
[--output-graph "<filename>"] output the dependency graph of included files in the
<filename> file (in graphviz's dot format)
[-C, --no-cxx] ignore C++ files (i.e. collect only C files)
<src> ... directory name(s) or file name(s) of C source(s) from which
selected definitions shall be extracted and collected in the
local database.
For example:
$ cd tests/
$ ccrawl -l test.db collect -a -C samples/
preprocessing files...
system file '/usr/lib/gcc/x86_64-linux-gnu/9/../../../../include/c++/9/iostream' is used
missing include file for 'h1.h'
missing include file for 'folder2/x.h'
system file '/usr/include/stdlib.h' is used
system file '/usr/include/stdio.h' is used
system file '/usr/lib/gcc/x86_64-linux-gnu/9/../../../../include/c++/9/cstddef' is used
missing include file for 'missingsys.h'
done.
[ 5%] samples/shahar.cpp [ 18]
[ 11%] samples/01_volatile.h [ 2]
[ 17%] samples/00_empty.h [ 0]
[ 23%] samples/auto.h [ 7]
samples/other/std.h
[ 29%] samples/xxx/graph.h [ 9]
[ 35%] samples/inclusion_err.h [ 2]
samples/bitfield.h
[ 41%] samples/code.c [710]
/usr/include/stdlib.h
/usr/include/stdio.h
samples/simple.h
[ 47%] samples/stru.h [ 1]
[ 52%] samples/fwd_decl.hpp [ 2]
[ 58%] samples/templates.hpp [413]
/usr/lib/gcc/x86_64-linux-gnu/9/../../../../include/c++/9/cstddef
[ 64%] samples/cxxabi.h [ 17]
[ 70%] samples/other/test.c [ 40]
samples/other/../header.h
samples/other/h2.h
[ 76%] samples/derived.hpp [ 4]
[ 82%] samples/constr.cpp [ 21]
samples/classes.hpp
[ 88%] samples/cxx.cpp [2394]
samples/wonza.hpp
/usr/lib/gcc/x86_64-linux-gnu/9/../../../../include/c++/9/iostream
[ 94%] samples/c_linkage.hpp [ 1]
[100%] samples/other/sys.h [ 0]
------------------------------------------------------------------------------------------------
saving database... [2776]
The resulting local database is stored as a TinyDB ‘test.db’ file. It contains definitions of all C/C++ files in the samples directory. As shown above, the preprocessing step reports missing included files as well as included system files.
Search¶
The search command performs a regular expression search within database ‘id’ and ‘val’ keys:
$ ccrawl [global options] search <rex>
<rex> python (re) regular expression matched against local database
documents keys 'id' and 'val'. Documents are filtered with
'tag' as well if the --tag global options is used.
For example:
$ ccrawl -l test.db search ".*_my"
found cStruct identifer "struct _mystruct" with matching value
found cTypedef identifer "mystruct" with matching value
found cUnion identifer "union _myunion"
found cTypedef identifer "myunion" with matching value
Select¶
The select command performs advanced queries within the local database:
$ ccrawl [global options] select [-a, --ands <str>]
[-o, --ors <str>]
[<select_command> [options] [args]]
[-a, --ands <str>] filters <str> of the form "key=value" added to current query
with operator AND:
Equivalent to "Q &= where(key).search(value)".
[-o, --ors <str>] same form, but added to current query with operator OR:
Equivalent to "Q |= where(key).search(value)".
<select_command>:
prototype "<pos>:<type>" ...
Find prototypes (cls=cFunc) for which constraints of the form
"<pos>:<type>" matches. Such constraint indicates that
argument located at <pos> index has C type <type>
(position index 0 designates the return value of the function).
constant [-m, --mask] <value>
Find which macro definition or enum field name matches constant <value>.
Option --mask allows to look for the set of macros or enum symbols
that equals <value> when OR-ed.
struct [-d, --def] [-p, --pointer {4 or 8}] "<offset>:<type>" ...
Find structures (cls=cStruct) satisfying constraints of the form:
"<offset>:<type>" where offset indicates a byte offset value (or '*')
and type is a C type name, symbol '?', '*' or a byte size value:
If <type> is "?", match any type at given offset,
If <type> is "*", match any pointer type at given offset,
If <type> is "+<val>", match if sizeof(type)==val at given offset.
If "*:+<val>", match struct only if sizeof(struct)==val.
Option --def outputs the definitions of found types rather than
their identifiers.
For example:
$ ccrawl -l test.db select constant -s "MY" 0x10
MYCONST
$ ccrawl -l test.db select struct -p 8 "*:+104"
[####################################] 100%
class X::D
struct _mystruct
$ ccrawl -l test.db select -a id="class X::D" struct -p 8 -d "*:+104"
struct __layout$X::D {
void *__vptr$C1;
int c;
void *__vptr$C2;
int cc;
int x;
int ccc;
int d;
void *__vptr$V1;
int a;
void *__vptr$A2;
int aa;
int v;
void *__vptr$V3;
void *__vptr$V2;
int b;
int bb;
int vv;
};
Show¶
The show command allows to recursively output a given identifier in various formats:
$ ccrawl [global options] show [options] <identifier>
options: [-r, --recursive] recursively include all required definitions in the output
such that type <identifier> is fully defined.
[-f, --format <fmt>] use output format <fmt>. Defaults to C, other formats are
"ctypes", "amoco".
For example:
$ ccrawl -l test.db show -r 'struct _mystruct'
typedef unsigned char xxx;
typedef xxx myinteger;
struct _mystruct;
typedef int (*foo)(int, char, unsigned int, void *);
enum X {
X_0 = 0,
X_1 = 1,
X_2 = 2,
X_3 = 3
};
struct _bar {
enum X x;
};
struct _mystruct {
myinteger I;
int tab[12];
unsigned char p[16];
short *s;
struct _mystruct *next;
foo func;
struct _bar bar[2];
};
Info¶
The info command provides meta-data information about a given identifier. For structures
the offsets and sizes of every field is displayed if all subtypes are defined:
$ ccrawl [global options] info [options] <identifier>
options: [-p <size>] size (4 or 8) of pointers used to compute fields' offsets for
info on structures
For example:
$ ccrawl -l test.db info -p 8 'struct _mystruct'
identifier: struct _mystruct
class : cStruct
source : samples/header.h
tag : xxx
size : 104
offsets : [(0, 1), (4, 48), (52, 16), (72, 8), (80, 8), (88, 8), (96, 2)]
[using 64 bits pointer size]
Graph¶
The graph command outputs the dot-format dependency graph associated to a given type.
the graph nodes are the types names and edges show the dependency from one type to another,
ie essentially the structures’ field (and pointer accessor) that binds those types:
$ ccrawl [global options] graph [options] <identifier>
options: [-o <file>] output filename (defaults to stdout)
For example (see samples/xxx/graph.h) :
$ ccrawl -l test.db graph 'struct grG'
//graph is connected
//graph has a strongly connected component of size 3
//graph has a strongly connected component of size 4
digraph {
rankdir="LR"
node [style="rounded"]
v0 [label="struct grG" shape="box"]
v1 [label="sA" ]
v2 [label="struct grA" shape="box"]
v3 [label="pA" ]
v4 [label="missing" color="red"]
v5 [label="pB" ]
v6 [label="struct grB" shape="box"]
v7 [label="pG" ]
v0 -> v1 [label="a"]
v1 -> v2 [style="dashed"]
v2 -> v3 [label="next"]
v3 -> v1 [label="*" color="blue"]
v2 -> v4 [label="**t"]
v0 -> v5 [label="*tb"]
v5 -> v6 [label="*"]
v6 -> v7 [label="g"]
v7 -> v0 [label="*" color="blue"]
v6 -> v2 [label="a[3]"]
}
which results in:
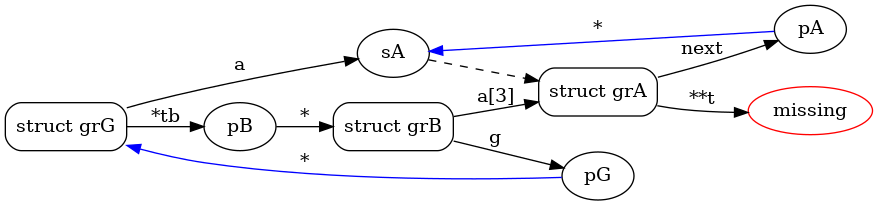
In the output graph, structures have rounded box, other types are just rounded. If the type is missing from the database, the node is colored in red. Edges are possibly associated with an “accessor” like here the field named a in struct grG is of type sA. Indeed, we have:
For example:
struct grG {
int n;
sA a;
pB *tb;
};
Note that primitive types are always ignored (the int n field does not appear in the graph.) An accessor can also be a[3] like the one between struct grB and struct grA or simply an “anonymous” pointer dereference in the case of a type definition like typedef stuct grG *pG. Finally, edges that are directed “backward” are colored in blue. The first lines of the output are comments that indicate if the graph is “connected” and if it has some non-trivial strongly connected components (basically cycles).